Recently I’ve been working with one small application that would gradually become slower and slower. While there were many reasons for it to happen, I found one of them interesting.
To give you a bit of context: the application was a simple single topic legacy Kafka consumer. I rewrote it to Karafka, and all of the logic looks like this:
class EventsConsumerAnd the processor looks like so (I removed all the irrelevant code):
class Processor def initialize @queue = Queue.new @worker = Thread.new { work } end def call(events) # do something with events results = complex_inline_computation(events) @queueSo, we have a Karafka consumer with a processor with one background thread supposed to flush the data async. Nothing special, and when putting aside potential thread crashes, all looks good.
However, there is a hidden problem in this code that can reveal itself by slowly degrading this consumer performance over time.
Karafka uses a single persistent consumer instance per topic partition. When we start processing a given partition of a given topic for the first time, a new consumer instance is created. This by itself means that the number of threads we end up with is directly defined by the number of topics and their partitions we’re processing with a single Karafka process.
If that was all, I would say it’s not that bad. While for a single topic consuming process, with 20 partitions, we do end up with additional 20 threads, upon reaching this number, the degradation should stop.
It did not.
There is one more case where our legacy consumer and Karafka would spin-up additional threads because of the processor re-creation: Kafka rebalance. When rebalancing happens, new consumer instances are initialized. That means that each time scaling occurred, whether it would add or remove instances, a new processor thread would be created.
Fixing the issue
Fixing this issue without a re-design is rather simple. As long as we can live with a singleton and we know that our code won’t be executed by several threads in parallel, we can just make the processor into a singleton:
While it is not the optimal solution, in my case it was sufficient.
Performance impact
One question remains: what was the performance impact of having stale threads that were doing nothing?
I’ll try to answer that with a more straightforward case than mine:
require 'benchmark' MAX_THREADS = 100 STEP = 10 ITERS = 50000000 (0..MAX_THREADS).step(STEP).each do |el| STEP.times do Thread.new do q = Queue.new q.pop end end unless el.zero? # Give it a bit of time to initialize the threads sleep 5 # warmup for jruby - thanks Charles! 5.times do ITERS.times do ; a = "1"; end end Benchmark.bm do |x| x.report { ITERS.times do ; a = "1"; end } end endI’ve run this code 100 times and used the average time to minimize the randomness impact of other tasks running on this machine.
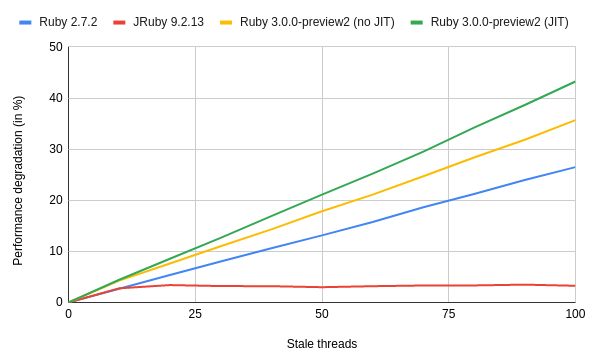
Here are the results for Ruby 2.7.2, 3.0.0-preview2 (with and without JIT) and JRuby 9.2.13, all limited with
time taskset -c 1, to make sure that JRuby is running under the same conditions (single core):CRuby performance degradation is more or less linear. The more threads you have that do nothing, the slower the overall processing happens. This does not affect JRuby as JVM threads support is entirely different than the CRubys.
What worries me more, though, is that Ruby 3.0 seems to degrade more than 2.7.2. My wild guess here is that it’s because of Ractors code’s overhead and other changes that impact threads scheduler.
Below you can find the time comparison for all the variants of CRuby:
It is fascinating that 3.0 is slower than 2.7.2 in this case, and I will try to look into the reasons behind it in the upcoming months.
Note: I do not believe it’s the best use-case for JIT, so please do not make strong claims about its performance based on the charts above.
Summary
The more complex applications you build, the bigger chances are that you will have to have threads at some point. If that happens, please be mindful of their impact on your applications’ overall performance.
Also, keep in mind that the moment you introduce background threads, the moment you should introduce proper instrumentation around them.
Cover photo by Chad Cooper on Attribution 2.0 Generic (CC BY 2.0) license.
The post The hidden cost of a Ruby threads leakage appeared first on Running with Ruby.
The latest interim release of Ubuntu introduces “devpacks” for popular frameworks like Spring, along with…
Ubuntu 25.04, codenamed “Plucky Puffin”, is here. This release continues Ubuntu’s proud tradition of integrating…
Ubuntu released its 20.04 (Focal Fossa) release 5 years ago, on March 23, 2020. As…
Focal Fossa will reach the End of Standard Support in May 2025, also known as…
Ubuntu MATE 25.04 is ready to soar! 🪽 Celebrating our 10th anniversary as an official…
Welcome to the Ubuntu Weekly Newsletter, Issue 887 for the week of April 6 –…
{kind=link}
{kind=link}